
티스토리 뷰
[네트워크] 주소창에 네이버 검색시 일어나는 일
hyeon.q 2024. 2. 13. 00:03
1. 들어가며
오늘은 주소창에 www.naver.com을 검색하면 일어나는 일에 대해서 알아보겠습니다.
평소에 모든 사람들이 웹서핑을 하든, 검색을 하든 url창에다가 인터넷 주소를 검색하는 일이 자주 있을 것입니다.
요즘은 캐시를 이용하여, 본인이 검색한 URL 주소들을 브라우저에서 기억하고 있어,
naver에 nav 만 입력해도 아래 검색 목록에 뜨는 경우를 많이 접할 것입니다.
그리고 본인이 웹 개발자라면은 만든 웹 사이트를 사람들에게 보여줘야 할 것입니다.
원초적으로, 내가 코드를 짜고, 테스트를 하고 배포를 한 후에, 배포를 한 사이트를 사람들이 url주소 검색하면은
어떻게 그 사이트로 들어가지게 되는 걸까?라는 고민을 해본 적이 있나요?
저는 최근에 궁금증이 생겨 여러 가지 방향을 생각해 봤습니다.
- 네트워크 관점
- 인프라 관점
큰 틀에서 2가지 관점으로 고민을 할 수 있다고 생각을 했습니다.
내가 네이버를 검색을 했는데, 페이지가 뜨지 않았습니다.
그러면 여러분들은 어떻게 하실 건가요?
일반인들은 보통 껐다 켜기를 반복할 테지만
개발자는 과정을 이해하고 알아야 하는 사람이므로,
왜 페이지가 뜨지 않을까?
라는 고민을 가지고 디버깅을 진행 해야 합니다.
2. 본론
1. 클라이언트 요청.
그 요청한 데이터들이 클라이언트 네트워크에 OSI7계층에서 부터 데이터 요청을 시작하여
최상위 계층인 응용계층 7계층 부터 6계층, 5계층 쭉 내려가서 1계층 물리 계층까지 내려가게 됩니다
그 과정에서 1계층까지 요청이 도착하면, 요청 정보를 담은 메세지는 패킷 이라는 단위로 변하게 됩니다.
위 내용을 잘 모르겠다면은 OSI7계층을 꼭 공부해보셔야 합니다.
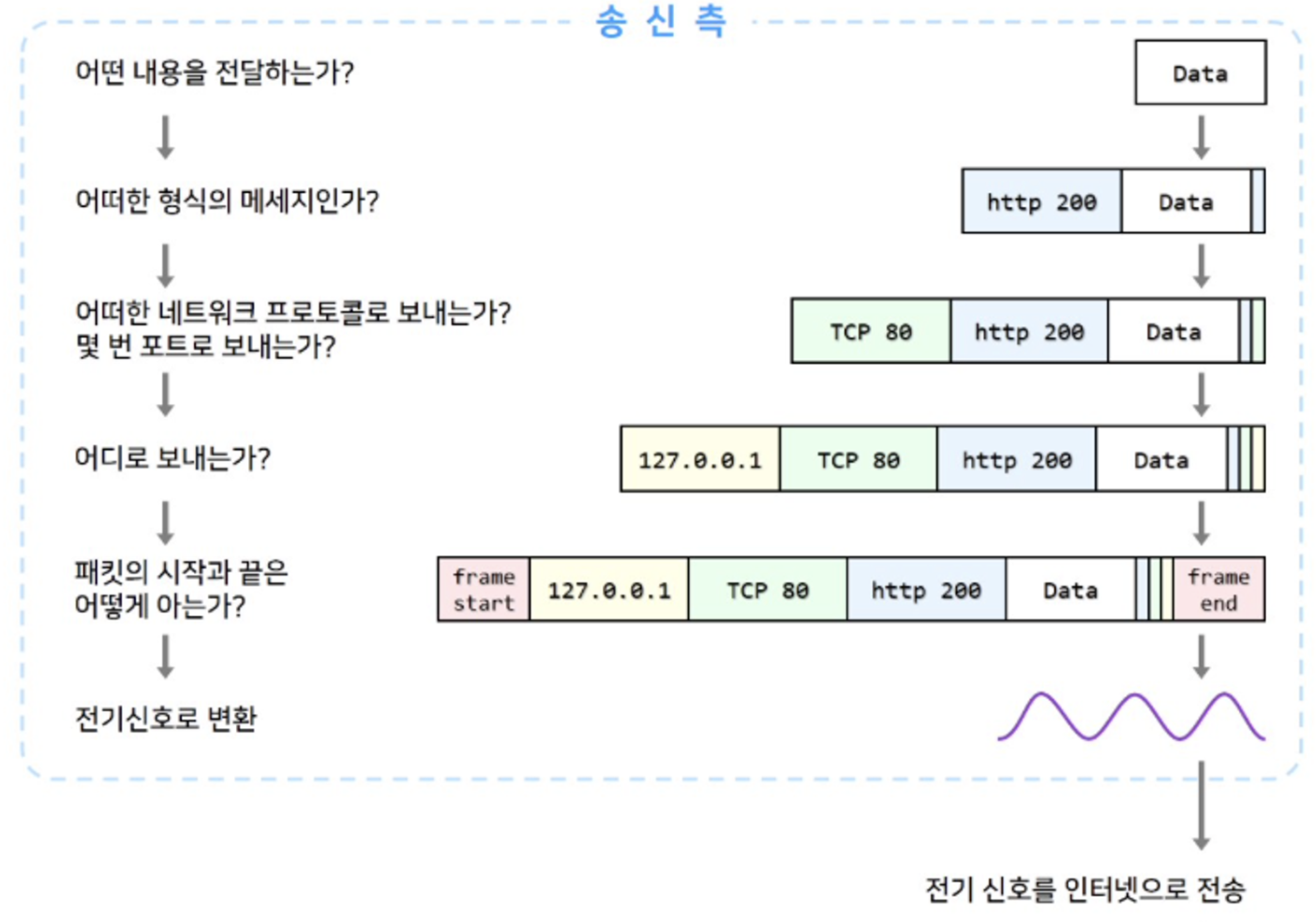
위 과정을 간단하게 사진으로 보면 위 구조로 볼 수 있습니다.
클라이언트가 요청을 했으니, 이제 서버는 응답을 해야합니다.
그 과정은 요청하는 것과 정 반대라고 생각하시면 편합니다.
응답을 할 때는 1계층부터 ~ 7계층 까지 순서대로 올라가서 클라이언트에게 응답을 주는 것입니다.
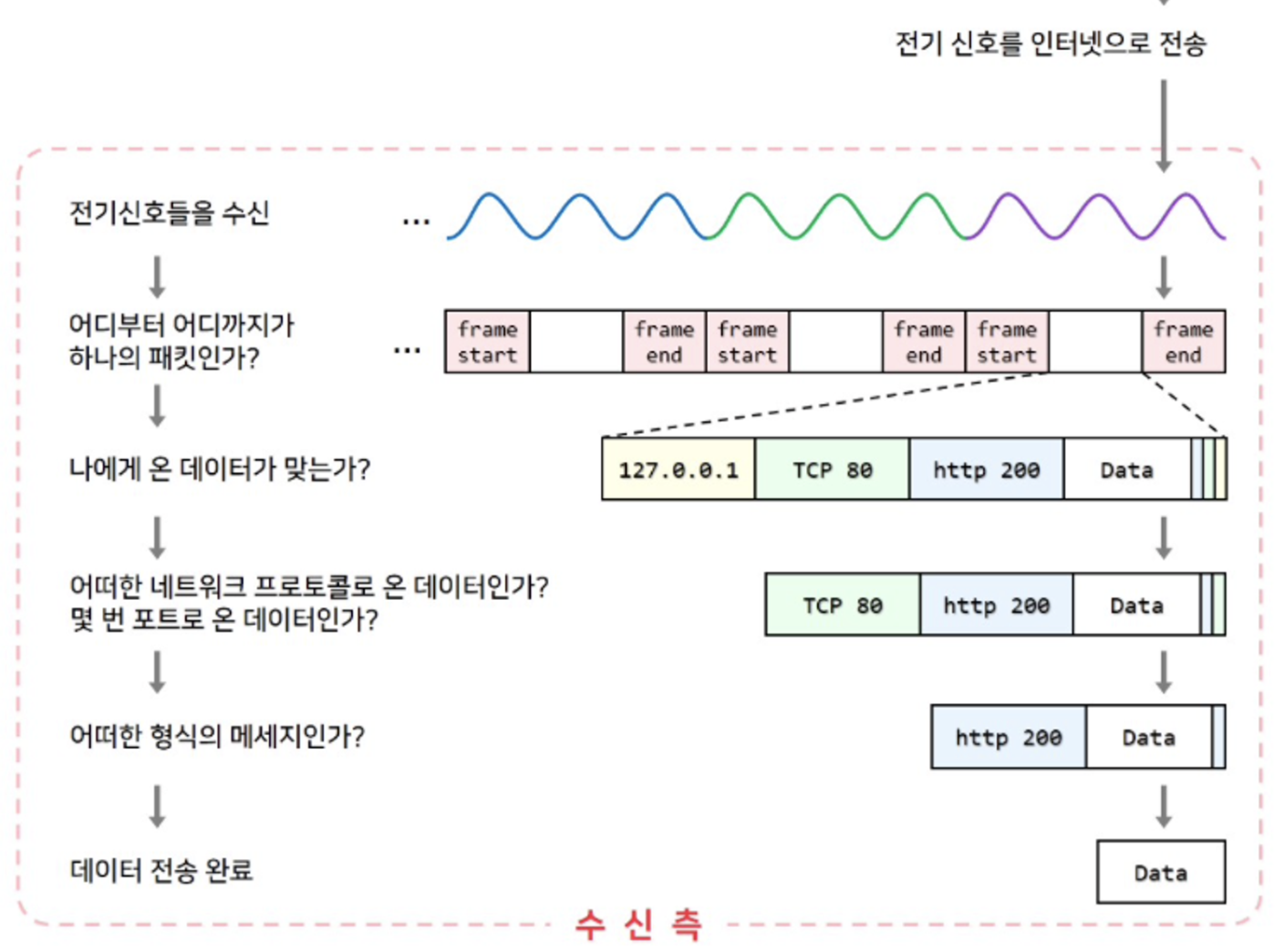
더 자세하게 알아보면 아래와 같은 내용들이 있습니다.
1. 리다이렉트
Redirect가 있다면 Redirect를 진행하고 없다면 그대로 해당 요청에 대한 과정이 진행됩니다.
2. 캐싱
해당 요청이 캐싱이 가능한지 가능하지 않은지를 파악합니다.
캐싱이 이미 된 요청이라면 캐싱된 값을 반환하며 캐싱이 되지 않은 새로운 요청이라면 그 다음 단계로 넘어간다. 캐싱은 요청된 값의 결과값을 저장하고 그 값을 다시 요청하면 다시 제공하는 기술이다.
이는 브라우저 캐시와 공유 캐시로 나뉩니다.
→ 위에서 살짝 설명했던 내용이 나옵니다.
브라우저 캐시
쿠키, 로컬스토리지 등을 포함한 캐시 입니다. 즉 개인 캐시라고도 합니다.
브라우저 자체가 사용자가 HTTP를 통해 다운로드 하는 모든 문서를 보유하는 것을 말합니다.
ex) 네이버를 자주 방문하므로, 네이버를 url에 검색하면 엄청 빠르게 사이트가 뜹니다.
이게 바로 브라우저캐시 입니다.
인터넷 사용기록을 삭제하고 싶어서, 삭제하면 사라지는게 바로 브라우저캐시 입니다.
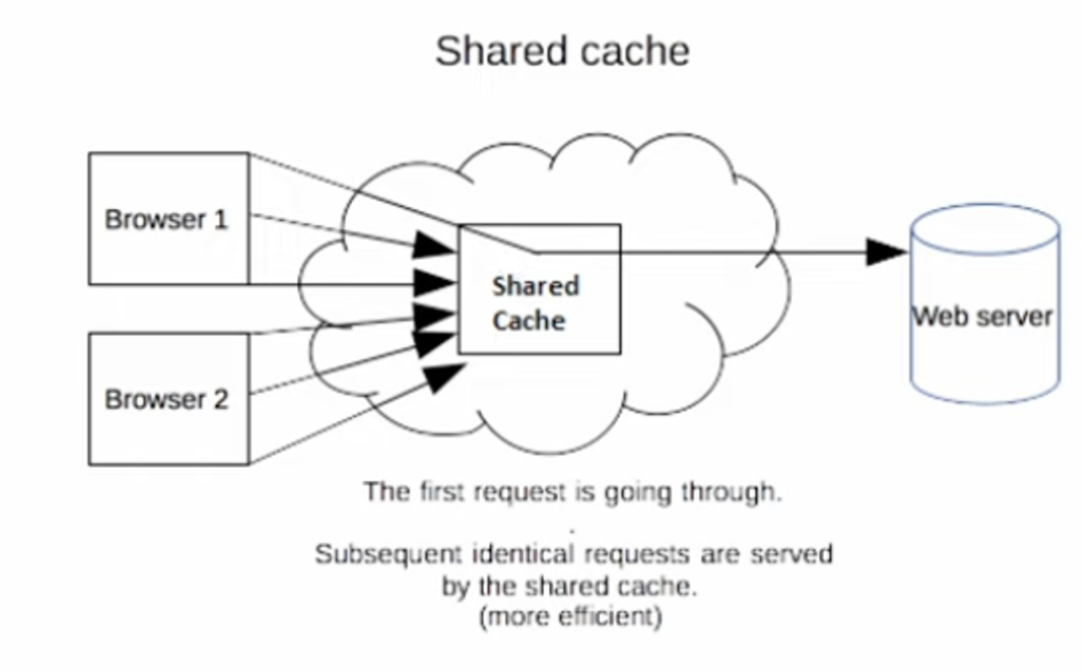
공유캐시
클라이언트와 서버 사이에 있으며 사용자간에 공유할 수 있는 응답을 저장할 수 있습니다.
대표적인 예시로 요청한 서버 앞단에 프록시서버가 캐싱을 하는 것을 말합니다.
이를 리버스 프록시를 둬서 내부서버로 포워드한다고도 말합니다.
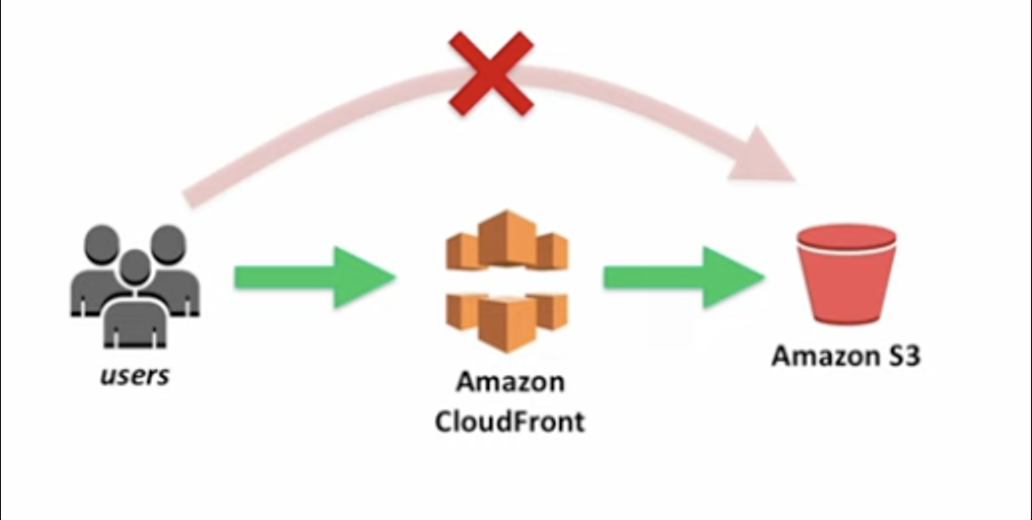
서버 앞단에 캐싱서버를 두고 클라이언트 요청시 서버로 요청이 가지않고 캐싱서버에서 요청을 받으면
내가 해결할 수 있으며 해결을 하고, 해결을 못하면 서버로 보내는 형식이다.
3. DNS
계층적인 도메인 구조와 분산된 데이터베이스를 이용한 시스템으로 FQDN을 인터넷 프로토콜인 IP로 바꿔주는 시스템 입니다.
이는 DNS관련 요청을 네임서버로 전달하고 해당 응답값을 클라이언트에게 전달하는 리졸버, 도메인을 IP로 변환하는 네임서버 등으로
이루어져있습니다.
그럼 FQDN은 뭘까요??
호스트 + 도메인이 합쳐진 완전한 도메인을 말합니다.
www : 호스트
naver.com : 도메인
즉FQDN을 통해서 위를 합치는 것 입니다.
컴퓨터와 컴퓨터는 IP주소를 기반으로 통신하기 때문에 위 주소를 합친 주소를 IP로 바꾸어주어야 합니다.
그 주소를 IP로 바꾸는 작업이 바로 DNS 입니다.
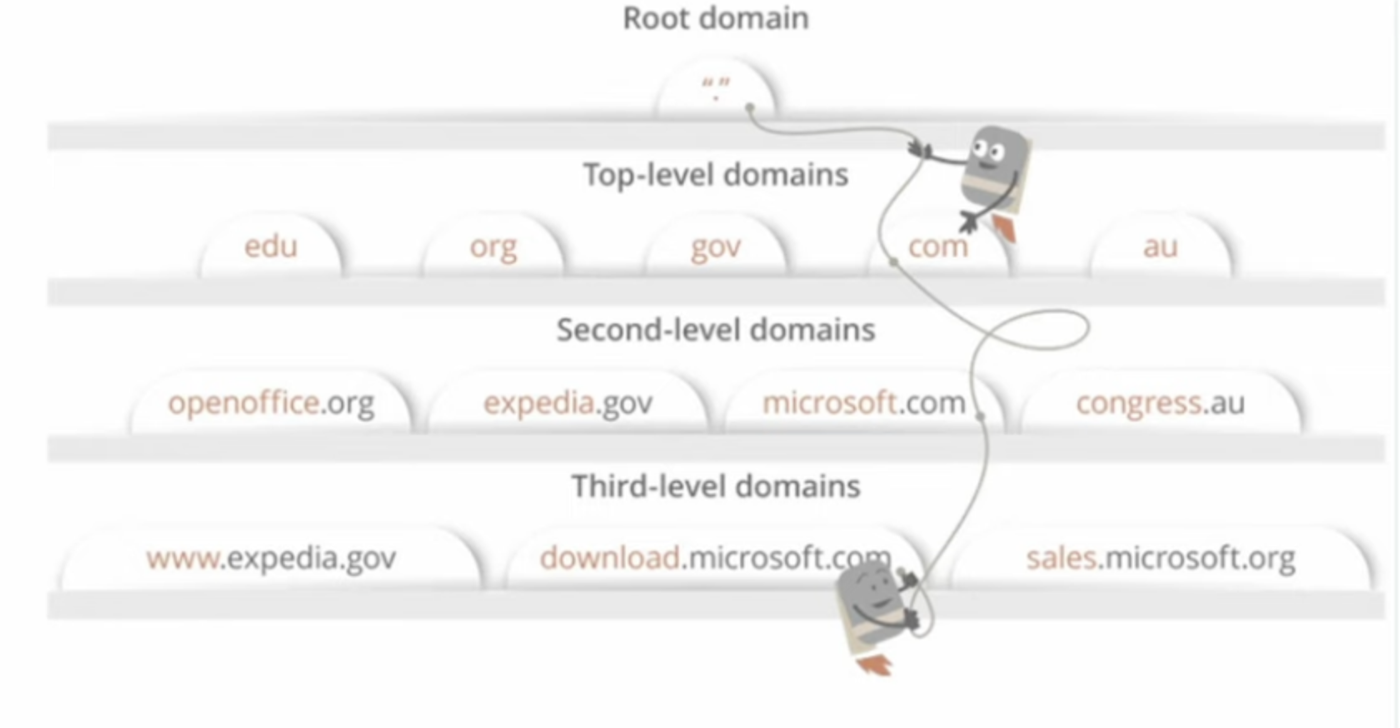
com부터 시작해서 ~ www 까지 역순으로 한개씩 거치며 완벽한 주소를 찾아가는 과정 입니다.
www.naver.com 는 127.127.000.000 이라는 어떠한 IP주소를 가지고 있을 것 입니다.
DNS 캐싱
미리 해당 도메인 이름을 요청한적이 있다면 로컬PC에 자동적으로 저장됩니다.
브라우저캐싱과 OS캐싱이 있습니다.
즉 DNS를 통해서, url(=문자열)을 ip주소로 변환을 합니다.
IP라우팅
- 해당 IP를 기반으로 라우팅, ARP 과정을 거쳐 실제 서버를 찾음
TCP 연결구축
- TCP Socket을 Open 합니다
- Https 요청이라면 TLS handshake 과정을 통해 연결을 설정한다.
- 브라우저가 http요청이라면
- TCP 3way - 3way 핸드쉐이킹 및 SSL연결등을 통해 연결을 설정합니다.
- 이 후 요청을 보낸 후 요청한 서버로부터 응답을 받습니다.
콘텐츠 다운로드
- 요청한 컨텐츠 서버로부터의 다운받습니다.
여기까지가 TTFB 라고도 합니다.
브라우저 렌더링
- 받은 데이터를 바탕으로 브라우저 엔진이 브라우저렌더링과정을 거쳐 화면을 만듭니다.
위 내용은 알아두면 정말 유용하다고 생각합니다.
Point
1. 도메인은 사람이 읽기 쉬운 주소이고, IP는 컴퓨터가 인식하는 숫자 주소로, 도메인은 IP 주소로 매핑되어 인터넷에서 서버를 찾을 수 있게 한다.
2. 도메인과 IP 주소의 매핑은 DNS (Domain Name System)서버에 의해 이루어진다. DNS 서버는 도메인 이름을 해당하는 IP 주소로 변환하여 인터넷에서 요청된 리소스를 찾을 수 있게 한다.
REF
1. https://www.youtube.com/watch?v=YahjHM9UNCA&t=63s
2. https://velog.io/@emplam27/CS-그림으로-알아보는-네트워크-계층화와-OSI-TCPIP-UDP의-특징과-차이점